Construção do Modelo de Visão Computacional
Introdução
Após o pré-processamento das imagens, utilizamos o conjunto de dados resultante — já com as melhorias de contraste, remoção de ruído e realce das fissuras — como base para o treinamento do nosso modelo de visão computacional. Essa integração entre pré-processamento e treinamento é fundamental, pois as melhorias aplicadas nas imagens visam justamente facilitar a detecção e a classificação das fissuras pelo modelo.
Treinar um modelo pode parecer complicado à primeira vista, mas hoje existem ferramentas que facilitam bastante esse processo. Um exemplo é o YOLO (You Only Look Once), uma biblioteca em Python que permite treinar modelos com poucas linhas de código.
A documentação oficial do YOLO é outro ponto forte da biblioteca, pois ela oferece suporte detalhado para diferentes configurações e aplicações. Trabalhando com o modelo, descobrimos que existem muitas variáveis que influenciam diretamente o desempenho do modelo após o treinamento, e você pode se aprofundar nelas através da Documentação do Yolo.
Qual o objetivo?
Nosso objetivo é utilizar o dataset já pré-processado para treinar um modelo YOLO capaz de detectar e classificar fissuras com precisão. Essa é uma etapa que exige muita atenção, pois envolve diversas variáveis que influenciam diretamente o desempenho final. Modelos de detecção, como o nosso, não apenas localizam objetos (neste caso, fissuras), mas também os classificam corretamente. Queremos que o modelo seja capaz de identificar a presença de fissuras de forma precisa e, principalmente, de classificá-las corretamente conforme suas características.
Treinamento
Para atingirmos um modelo capaz de identificá-las e classificá-las de maneira satisfatória, precisamos antes treiná-lo. Treinar um modelo com YOLO pode ser simples assim:
# Importando a biblioteca da Ultralytics para usarmos o YOLO
from ultralytics import YOLO
# Definindo a versão do YOLO que vamos usar para treino, saiba mais sobre outros modelos na documentação do YOLO
model = YOLO("yolov8n.pt")
# Definindo parâmetros de treino
model.train(
data="modelo.yaml", # Caminho para o arquivo de configuração do dataset
epochs=80, # Número de épocas
imgsz=640, # Tamanho das imagens
batch=16, # Tamanho do batch
name="modelo_fissuras", # Nome do experimento
project="treinamento_fissuras" # Diretório do projeto
)
Esse inclusive foi o primeiro código elaborado para treino pela equipe. Note que o comando train() recebe alguns parâmetros importantes. O principal deles é o arquivo "modelo.yaml", que define os caminhos para os conjuntos de treino e validação, além dos rótulos (labels) presentes nas imagens.
Outro parâmetro a se observar é o epochs, que indica quantas vezes o modelo irá percorrer todo o dataset. Um valor muito baixo pode resultar em um modelo pouco preciso, enquanto um valor muito alto pode causar sobreajuste (overfitting), principalmente se o conjunto de imagens for pequeno. No nosso caso, testamos diferentes quantidades até alcançar um resultado satisfatório.
Alguns parâmetros, quando ajustados, podem exigir mais poder computacional do seu computador, e isso gera mais tempo de espera para o treinamento ser concluído. As épocas são diretamente afetadas por isso. Por sorte, contamos com o "supercomputador" do nosso laboratório, que por possuir um poder computacional bem alto, tornou possível o teste do modelo com diferentes valores em cada um dos parâmetros. Isso nos permitiu perceber que teríamos que ajustar alguns parâmetros para chegarmos a um resultado legal de modelo. Nosso dataset era pequeno demais para mais de 100 épocas e isso ficava evidente quando víamos os resultados:
Figura 1 - Resultados de um dos nossos primeiros treinamentos
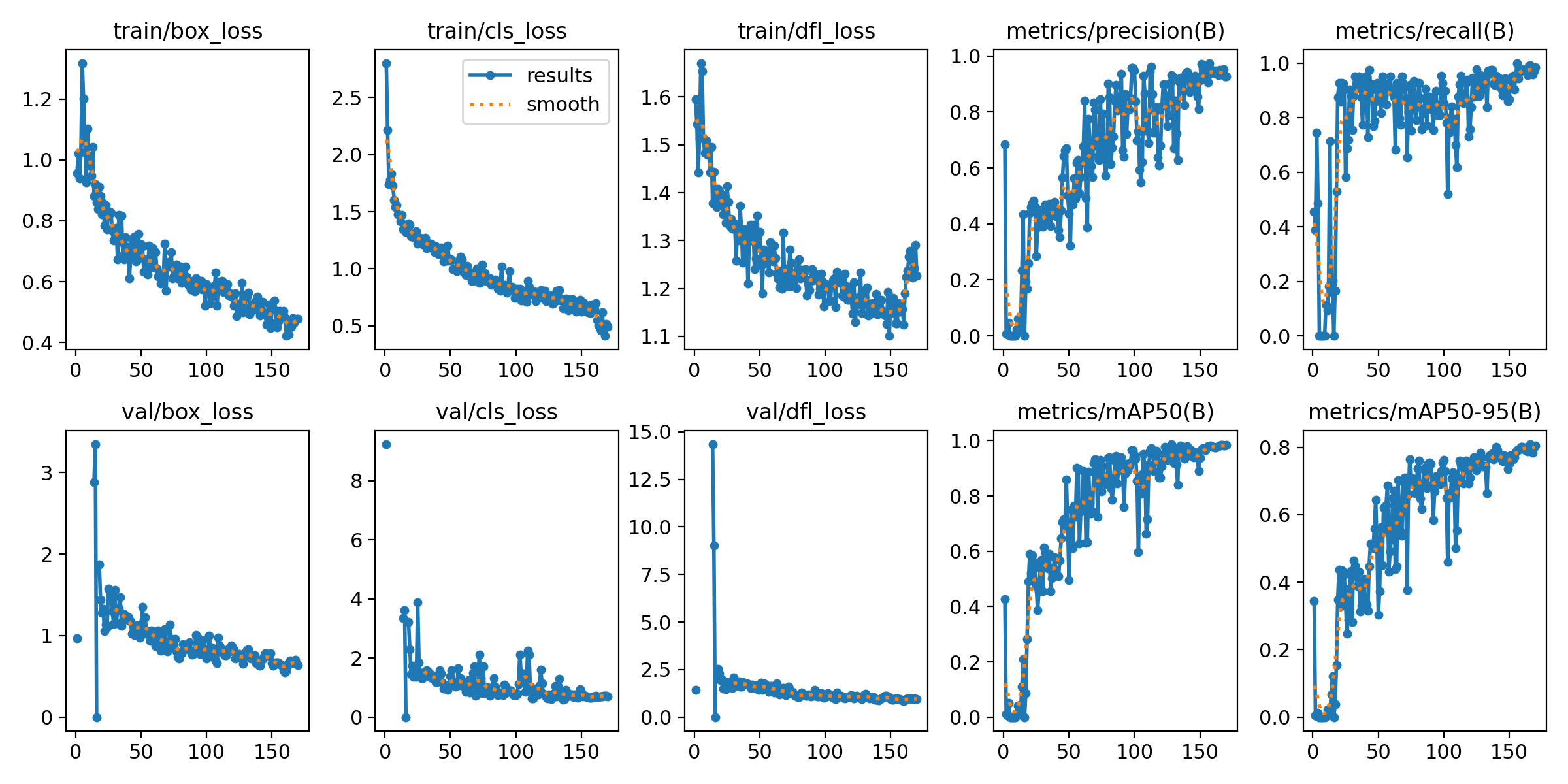
Fonte: Os autores (2025)
Essa imagem mostra os resultados obtidos em um treinamento com muitas épocas. Perceba que os gráficos não apresentam o comportamento esperado. Idealmente, após algumas épocas, as curvas de erro (como perda de validação e de treinamento) deveriam começar a cair de forma consistente, indicando que o modelo está aprendendo. No entanto, neste caso, os gráficos sugerem que o modelo não está evoluindo como o previsto, o que pode ser indício de sobreajuste, taxa de aprendizado inadequada ou problemas no dataset. Mas para compreendermos o comportamento do modelo, precisamos antes entender o que cada um desses gráficos quer dizer:
- Training Loss (box, obj, cls): Mostra como os erros do modelo durante o treino se comportam ao longo das épocas. O ideal é que essas curvas diminuam progressivamente.
- Validation Loss (box, obj, cls): Indica o erro do modelo ao ser avaliado com os dados de validação. Se essa curva começar a subir enquanto o erro de treino continua caindo, é sinal de sobreajuste.
- mAP50 e mAP50-95: Representam a média da precisão nas detecções. O valor de mAP@0.5 usa um limiar de IoU de 0.5, enquanto o mAP@0.5:0.95 é mais exigente, considerando múltiplos limiares. O ideal é que essas curvas cresçam ao longo do treinamento.
- Precision e Recall: Medem a qualidade das detecções. Precisão indica a proporção de verdadeiros positivos entre as predições positivas, e recall mostra quantas das ocorrências reais foram detectadas. O objetivo é que ambas aumentem com o tempo.
Até chegarmos no modelo final dessa sprint, foram muitos treinamentos. Cada integrante treinou ao menos 10 modelos diferentes, com diferentes combinações de parâmetros e valores. Conforme treinávamos os modelos, elaborávamos hipóteses de parâmetros que poderiam estar influenciando positivamente ou negativamente o resultado do modelo.
Escolha do Modelo
Embora a escolha de utilizar o YOLO tenha sido fácil, ainda era necessário tomar outras decisões importantes. A partir da versão v5, o YOLO passou a oferecer diferentes tamanhos de modelos: nano (n), small (s), medium (m), large (l) e extra large (x). Cada variante representa um equilíbrio distinto entre desempenho e consumo de recursos, influenciando diretamente tanto o tempo de treinamento quanto a eficiência na inferência. Atualmente, o YOLO encontra-se na versão v11.
Para este projeto, utilizamos o modelo YOLOv8n, a versão nano do YOLOv8. Tomamos essa decisão pelo tamanho reduzido do nosso dataset e na necessidade de realizar múltiplos testes em pouco tempo. O YOLOv8n é otimizado para velocidade e baixo consumo computacional, ideal para essa primeira etapa do nosso protótipo.
Estratégia de Validação
A validação dos nossos modelos foi feita principalmente por meio dos resultados gerados automaticamente pelo próprio YOLO após o treinamento. Esses resultados incluem gráficos e métricas que nos ajudaram a entender o comportamento do modelo em diferentes configurações e ajustes. São resultados importantes para guiar nossas decisões durante os testes.
Como esses resultados merecem uma análise mais aprofundada, trataremos disso em um documento específico dedicado à interpretação dos outputs gerados pelo modelo, ainda nesta seção do Docusaurus. Lá, explicamos como avaliamos o desempenho com base nas curvas de perda, métricas de precisão e exemplos visuais das detecções feitas.
Melhorias Para as Próximas Sprints
Como mencionado anteriormente, o modelo ainda apresenta algumas limitações que não puderam ser resolvidas nesta sprint. Um dos principais problemas é a detecção incorreta de objetos que não são fissuras, como pessoas ou elementos da estrutura, que acabam sendo classificados como fissuras. Embora o modelo apresente um bom desempenho quando exposto a imagens reais de fissuras, esses falsos positivos ainda precisam ser tratados.
Outro ponto importante é o baixo desempenho do modelo durante a execução em vídeo síncrono, o que atrapalha a fluidez da detecção em tempo real. Sabemos que isso pode ser otimizado com ajustes ou com o uso de versões mais leves do modelo.
É claro que, no curto prazo, podemos contornar isso com medidas paliativas, alertando que imagens contendo pessoas não devem ser enviadas ao sistema. No entanto, nosso objetivo é que o modelo seja capaz de atender a diferentes cenários de uso, conforme as necessidades do IPT. Por isso, essas questões serão priorizadas nas próximas sprints.
Referências
ULTRALYTICS. YOLOv8 — Overview. Disponível em: https://docs.ultralytics.com/pt/models/yolov8/#overview. Acesso em: 13 maio 2025.
ULTRALYTICS. YOLOv8 — Modo de Treinamento. Disponível em: https://docs.ultralytics.com/pt/modes/train/. Acesso em: 13 maio 2025.
ULTRALYTICS. YOLOv5 Releases – GitHub. Disponível em: https://github.com/ultralytics/yolov5/releases?utm_source=chatgpt.com. Acesso em: 13 maio 2025.
RAMESH, R. Understanding Hyper-parameter Tuning of YOLOs. Towards AI, 2023. Disponível em: https://pub.towardsai.net/understanding-hyper-parameter-tuning-of-yolos-82aec5f6e7b3. Acesso em: 13 maio 2025.