Resultados do Modelo
Introdução
Durante o desenvolvimento do projeto, foram realizados diversos treinamentos, ajustes de parâmetros e testes com diferentes versões do modelo para encontrar a melhor solução possível para a classificação das fissuras. Esse processo exigiu uma série de análises para garantir que o modelo tivesse um bom desempenho, tanto em precisão quanto em capacidade de classificar fissuras em situações variadas.
Contexto do dataset
Um dos desafios enfrentados durante o desenvolvimento foi a quantidade limitada de imagens disponibilizadas pelo parceiro do projeto, o IPT. Para superar essa limitação, não nos restringimos apenas ao conjunto original de imagens. Ao longo do processo, geramos aproximadamente 100 novas imagens de fissuras, divididas entre 50 fissuras de retração e 50 térmicas.
Além disso, realizamos uma nova rotulagem completa de todo o dataset, incluindo as imagens originais e as recém-geradas. Esse trabalho cuidadoso teve como objetivo garantir que as fissuras fossem anotadas com maior precisão, assegurando a qualidade dos dados para o treinamento.
Esse reajuste do dataset foi fundamental para melhorar os resultados dos treinamentos, possibilitando que os modelos pudessem aprender com uma base mais rica e representativa, aumentando assim a capacidade de classificação correta das fissuras.
Processo de Treinamento e Ajustes do Modelo
Com o dataset ampliado e rotulado, iniciamos os treinamentos do modelo usando o YOLOv8 na versão nano, que é mais leve e adequada para nosso volume de dados.
Realizamos vários testes, variando parâmetros importantes como número de épocas, tamanho do lote e tamanho das imagens, para entender como cada ajuste impactava o resultado final. Durante esse processo, acompanhamos métricas como perda, precisão e recall para verificar se o modelo estava aprendendo corretamente ou se havia problemas como sobreajuste.
Esse processo de testes e refinamentos nos permitiu escolher um modelo final que apresentou um desempenho satisfatório, equilibrando a precisão nas detecções com a capacidade de funcionar bem em imagens fora do conjunto de treino.
Análise dos Resultados
Durante os ciclos de treinamento, observamos que os gráficos de métricas apresentavam comportamentos instáveis e, em muitos casos, valores muito elevados, frequentemente ultrapassando os 90%. Apesar de, à primeira vista, esses números sugerirem um bom desempenho, eles indicavam um problema recorrente de overfitting, o que comprometia a capacidade do modelo de generalizar bem para novos exemplos.
A partir dessas evidências, foi necessário revisar o processo como um todo — refinando não apenas os parâmetros do treinamento, mas também a qualidade e variedade dos dados. Após esses ajustes, os resultados começaram a apresentar um comportamento mais consistente, com métricas estabilizadas em torno de 80%, valor mais condizente com a realidade do problema e que representa uma melhora na capacidade de generalização do modelo.
Os gráficos a seguir ilustram esse novo cenário, evidenciando como as melhorias aplicadas ao longo do projeto resultaram em um modelo mais equilibrado e confiável para a tarefa de classificação das fissuras.
Figura 1 - Gráficos do Modelo Escolhido
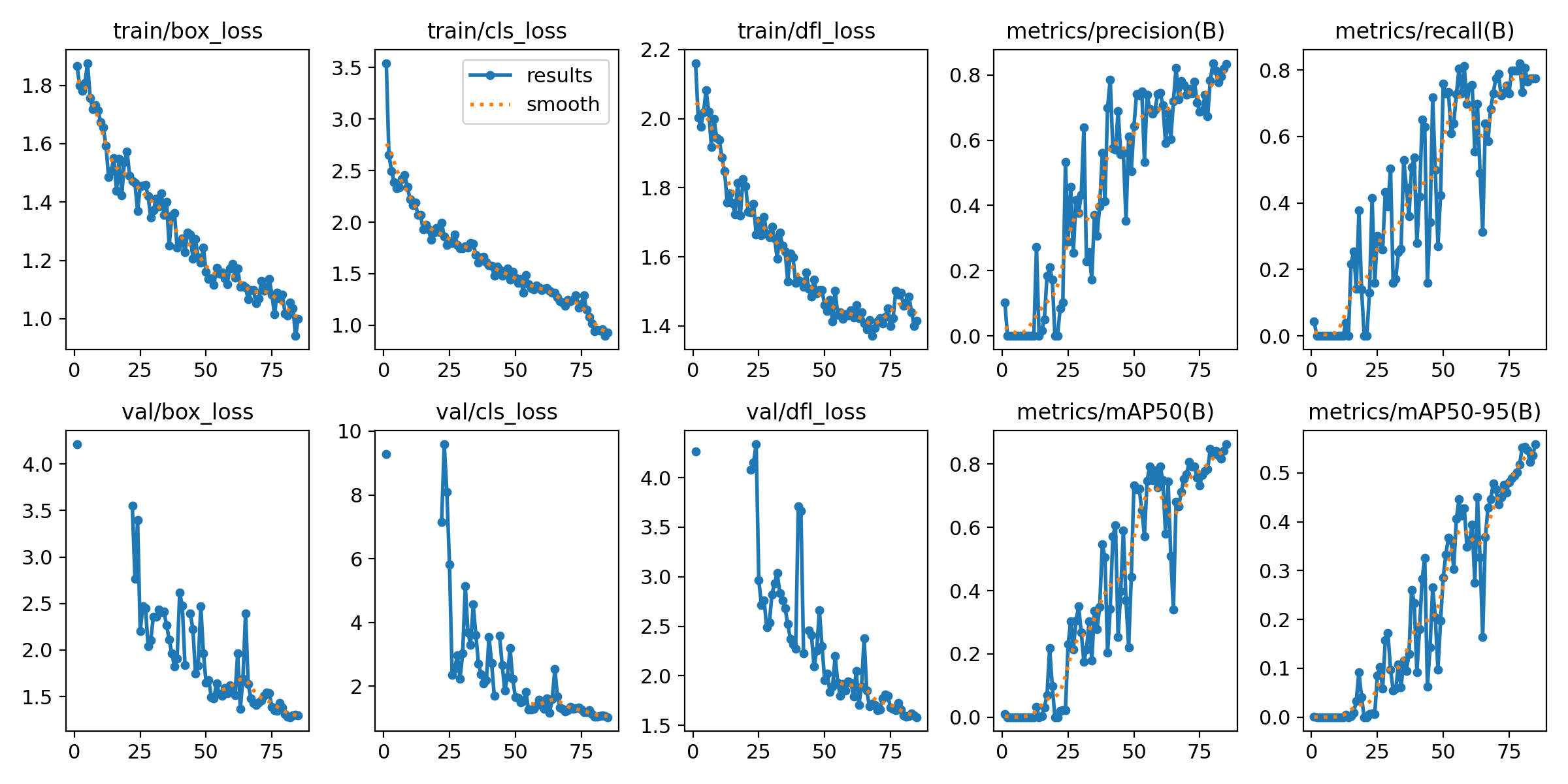
Fonte: Os autores (2025)
Agora, vamos analisar os principais gráficos que mostram o desempenho do modelo durante o treinamento e validação. Esses gráficos nos ajudam a entender como o modelo aprendeu a identificar as diferentes classes de fissuras e o quanto ele melhorou com o passar do tempo. Eles indicam se o modelo está aprendendo bem, se está cometendo muitos erros ou se está se ajustando demais aos dados de treino.
-
train/box_loss Mostra o erro do modelo ao tentar localizar as caixas que cercam as fissuras nas imagens de treino. Quanto menor, melhor, porque indica que o modelo está aprendendo a identificar corretamente onde as fissuras estão.
-
train/cls_loss Indica o erro na classificação das fissuras durante o treino. Valores baixos mostram que o modelo está ficando bom em diferenciar os tipos de fissura.
-
train/dfl_loss Reflete a precisão na previsão do formato das caixas delimitadoras durante o treino. Uma redução nesse valor indica que o modelo está ajustando melhor o tamanho e forma das caixas.
-
val/box_loss Semelhante ao train/box_loss, mas para o conjunto de validação. Ajuda a verificar se o modelo está acertando na localização das fissuras em dados que ele não viu durante o treino.
-
val/cls_loss Mostra o erro de classificação no conjunto de validação. Valores baixos indicam que o modelo consegue classificar corretamente as fissuras em imagens novas.
-
val/dfl_loss Reflete o ajuste do formato das caixas delimitadoras no conjunto de validação, ajudando a confirmar a qualidade da detecção fora dos dados de treino.
-
metrics/precision(B) É a medida que indica a proporção de classificações corretas entre todas as classificações feitas pelo modelo. Um valor alto significa que o modelo comete poucos erros ao afirmar que encontrou uma fissura.
-
metrics/recall(B) Mostra a capacidade do modelo de identificar todas as fissuras presentes nas imagens. Um valor alto indica que o modelo está encontrando a maioria das fissuras.
-
metrics/mAP05(B) Essa métrica avalia a precisão média do modelo com uma tolerância maior para a sobreposição da caixa prevista com a caixa real (IOU 0.5). Mede a eficácia geral da detecção.
-
metrics/mAP50-95(B) Avalia a precisão média considerando várias tolerâncias de sobreposição (IOU entre 0.5 e 0.95). É uma métrica mais rigorosa para testar a qualidade da detecção e classificação do modelo.
A observação dos gráficos gerados durante o treinamento mostrou que os valores de perda (loss) e das métricas de avaliação permaneceram em níveis baixos, mas dentro de uma faixa considerada adequada. Diferentemente das versões anteriores, nas quais os gráficos indicavam um comportamento típico de overfitting, neste treinamento os valores foram mais equilibrados entre os conjuntos, o que sugere uma aprendizagem mais generalizada por parte do modelo
A escolha da versão nano do YOLOv8 também se mostrou apropriada para o contexto atual do projeto, principalmente devido à quantidade limitada de imagens, mesmo após a expansão do dataset. O desempenho obtido confirma que, para uma base de dados mais enxuta, modelos mais leves tendem a apresentar melhores resultados e menor risco de sobreajuste.
Conclusão
O projeto evoluiu por meio de várias etapas de testes, ajustes e aprimoramentos, até alcançar um modelo capaz de classificar fissuras com desempenho satisfatório. A versão nano do YOLOv8 foi a escolhida neste momento, mas isso não significa que será a versão definitiva.
Ao longo das próximas sprints, o modelo continuará sendo aprimorado, com foco não apenas em melhorar a classificação, mas também a identificação das fissuras. O objetivo é seguir evoluindo a solução, buscando maior precisão em cenários reais.
Referências:
ULTRALYTICS. Ultralytics YOLO Documentation. Disponível em: https://docs.ultralytics.com. Acesso em: 15 maio 2025.
ULTRALYTICS. Ultralytics GitHub Repository. Disponível em: https://github.com/ultralytics/ultralytics. Acesso em: 15 maio 2025.