Primeiro Modelo
Como exposto no Business Model Canva, uma das atividades-chave da SOD é o "Desenvolvimento do algoritmo principal, com IA treinada para detecção e classificação de fissuras". Nesta sprint, o foco foi direcionado ao desenvolvimento do modelo de IA voltado especificamente para a classificação de fissuras, segunda etapa da atividade-chave prevista. O modelo treinado está na pasta [src/IA_classificacao/teachableMachine]. Nessa seção, visualizar-se-á o processo de criação deste primeiro modelo desde a escolha da Teachable Machine até a aplicação das métricas.
Por que usar a Teachable Machine?
O Teachable Machine é uma ferramenta web criada pelo Google Creative Lab - Experiments with Google para deep learning (Google, 2019). A ferramenta é baseada no TensorFlow.js e ajuda os usuários a criar e exportar modelos de classificação sem a necessidade de código (Google, 2019). Apesar de ter ferramentas para classificar imagens, sons e poses, para este projeto, a classificação de imagens foi suficiente.
Essa ferramenta foi a primeira candidata para o modelo de IA da SOD devido aos seguintes motivos:
- Facilidade de uso;
- Treinamento rápido;
- Confiabilidade do provedor (Google);
Observa-se que, por meio dessa plataforma, consegue-se treinar e avaliar um modelo confiável rapidamente. Sendo assim, foi possível angariar os primeiros resultados do pré-processamento apresentado na seção anterior antes da Review dessa sprint e assim, elaborar junto ao parceiro, hipóteses de filtro que melhorem o desempenho do algoritmo.
Treinando o modelo
Em vias de treinar o modelo, os seguintes passos foram tomados:
- Pré-processamento do dataset usando a função presente no arquivo [
src/IA_classificacao/preProcessamento/preProcessamento.py]; - Separação das imagens pré-processadas de forma randomizada em três categorias com balanceamento das classes:
- Treinamento (80%)
- Validação(10%)
- Teste(10%);
- Treinamento da Teachable Machine usando as duas classes (Retração e Térmicas), o conjunto de treinamento e as seguintes configurações:
- Épocas: 500
- Batch Size: 16
- Taxa de Aprendizado: 0,00209;
Essas configurações foram atingidas após diversos testes para melhorar as métricas de acurácia da validação
- Exportação do modelo treinado usando Keras.
Adequando o modelo
Após a exportação do modelo, era necessário, para atingir o RF01, uma função que recebesse apenas o caminho de uma imagem, a pré-processasse e devolvesse a previsão do modelo. Essa função está no arquivo [src/IA_classificacao/teachableMachine/prever.py].
Em primeiro lugar, o arquivo adequa a versão do modelo exportado pela Teachable Machine à versão mais recente do Tensorflow por meio de um algoritmo criado pelo usuário Jurgen_Thomas do Google AI Developers Forum no tópico "Cannot load .h5 model". Em seguida, a função prever é definida. Nela, carrega-se o modelo e os labels, e pré-processa-se a imagem usando a função processa_imagem apresentada na seção anterior.
Após isso, fez-se um pré-processamento adicional, necessário para modelos baseados na Teachable Machine, segundo o próprio guia da ferramenta:
- Converteu-se a imagem de volta para RGB e formato compatível com a biblioteca Pillow;
- Redimensiona-se a imagem para (224,224) e corta-se o centro
- Converte-se de volta para um array, normalizando-o.
Após esses passos, ainda é necessário enviar a imagem no formato aceito como input neste modelo: um array de 4 itens, sendo o primeiro a imagem; o segundo e o terceiro, o tamanho da imagem; e o último a quantidade de canais.
Previsão e Resultados
Após adequar e prever a classificação de cada uma das imagens do conjunto de validação, obteve-se o seguinte resultado:
Figura 1: Matriz de confusão - Validação
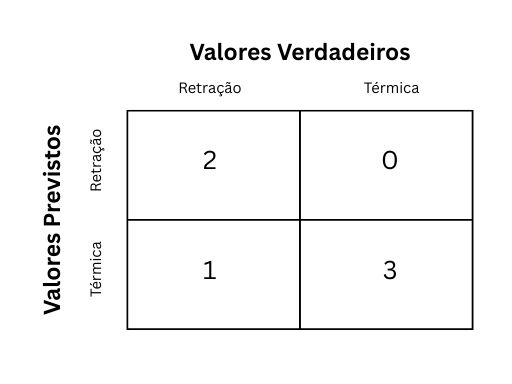
Fonte: Produzida pelos Autores (2025).
Neste link, você pode verificar a utilidade da Matriz de Confusão. A partir Figura 1, observa-se que a acurácia total do modelo é de 83,3%, entretanto, vê-se que a IA funciona melhor para fissuras térmicas do que de retração, não tendo, em relação ao primeiro, cometido quaisquer erros. O mesmo se verifica em relação aos resultados do conjunto de testes, como se observa no conjunto de testes:
Figura 2: Matriz de confusão - Testes
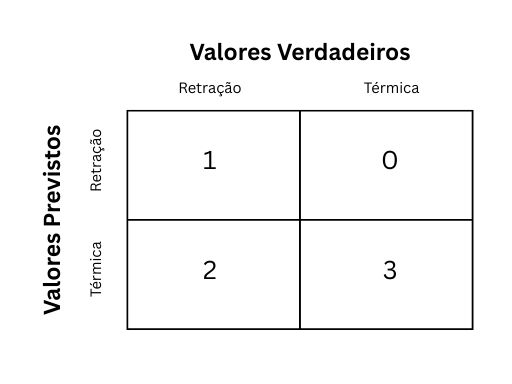
Fonte: Produzida pelos Autores (2025).
A Figura 2 mostra que, no caso dos testes, o modelo errou ainda mais em relação às fissuras de retração. Novamente, não obtém nenhum erro em relação às térmicas. Sua acurácia em relação aos testes está em 66,6%.
A média de acurácia do modelo, portanto, é de 75%. Em relação às outras métricas, têm-se a média:
Tabela 1: Métricas
| Métrica | Valor |
|---|---|
| Recall | 50% |
| Especificidade | 100% |
| Precisão | 100% |
| F1-Score | 66,7% |
Fonte: Produzida pelos Autores (2025).
Discussões e Conclusão
O modelo da Teachable Machine apresentou resultados moderados em relação ao esperado pela SOD. Nesta sprint, definiu-se o requisito não funcional 8 que se segue, conforme conversado para a maior entrega de valor para o parceiro:
O algoritmo de classificação de fissuras deve alcançar uma acurácia mínima de 85% nas imagens analisadas, conforme validação por inspeções humanas.
Evidentemente, a acurácia deste modelo ainda não atingiu a acurácia miníma exigida pelas regras de negócio. Deve-se notar, porém, que para o primeiro modelo desenvolvido pela SOD, criado a partir de um pré-processamento não ótimo - mesmo que advindo de um artigo científico - e resultado de uma ainda baixa expertise da equipe, os resultados obtidos foram considerados promissores.
CHUN, P. et al (2020) atinge uma acurácia de 99,7% na segmentação de fissuras. O problema de classificação da SOD, porém, é novo. Dessa forma, é mister maior expertise da equipe para o adequado pré-processamento da imagem e o teste de novos modelos. Isso será realizado na próxima sprint.
Não se pode deixar de observar, entretanto, que este modelo, evidentemente, privilegiou classificar imagens como fissuras térmicas. Em ambos os casos, teste e validação, não cometeu qualquer erro nessa classificação, de modo a atingir uma especificidade de 100%. Ademais, classificou muitas fissuras de retração como fissuras de térmicas de modo a reduzir o recall do modelo.
Após testes, compreendeu-se que esse viés não se dá devido à falta de balanceamento das classes. De fato, existem um número igual de imagens para as ambas classes. No entanto, a hipótese mais forte levantada pelo time é que isso ocorre devido à falta de diversidade do dataset, principalmente para imagens de retração.
Existem algumas figuras de retração como a apresentada acima em que os formatos geométricos aparecem com maior saliência. Embora a geometria da fissura seja um aspecto mais comum em fissuras térmicas., ela também pode aparecer nas figuras de retração. Logo, é necessário impedir que o modelo coloque peso nessa característica.
Nesse sentido, a SOD levantou algumas hipóteses acerca do objetivo do pré-processamento a ser realizado na próxima sprint. Eles estão apresentados abaixo.
O próximo pré-processamento deve evidenciar:
- As fissuras térmicas têm uma linha horizontal
- As fissuras térmicas têm manchas
- As fissuras de retração são mais fechadas
- As fissuras de retração não possuem uma linha horizontal de eixo
- As fissuras de retração "causam mais estrago"
Essas são apenas hipóteses. Consultar-se-á o parceiro na Sprint Review para validação
Em suma, o primeiro modelo desenvolvido pela SOD marca um passo inicial importante no uso de IA para classificação de fissuras. Apesar de ainda não atingir a acurácia desejada, os resultados obtidos servem como base sólida para melhorias futuras, especialmente com o aprimoramento do pré-processamento. Não obstante, a diversidade do dataset é uma limtação deste projeto.
Bibliografia
-
CHUN, P.; IZUMI, S.; YAMANE, T. Automatic detection method of cracks from concrete surface imagery using two‐step light gradient boosting machine. Computer-Aided Civil and Infrastructure Engineering, v. 36, n. 1, p. 61–72, 20 maio 2020.
-
GOOGLE. Teachable Machine. Disponível em: https://teachablemachine.withgoogle.com/.