Modelo de Visão Computacional - YOLO
Um dos requisitos para o funcionamento desse projeto é a detecção de resíduos dentro dos tubos, a fim de determinar o grau de impureza dentro dos reboilers. Para isso, utilizamos um modelo de visão computacional, o YOLOv8, que é voltado para a detecção de objetos em imagens em tempo real. Os motivos de escolha do modelo, bem como a definição de datasets e implementação da inteligência artificial serão descritos no decorrer dessa seção.
Escolha do Modelo
O YOLO (You Only Look Once) é um modelo de visão computacional voltado para a detecção de objetos em imagens em tempo real. Proposto por Joseph Redmon e Ali Farhadi em 2015, o YOLO foi escolhido por sua velocidade e precisão na detecção de objetos, sendo capaz de processar imagens a uma taxa de 45 frames por segundo. Além disso, sua capacidade de operar em tempo real é crucial para o contexto do projeto. Comparado a outros modelos de detecção de objetos, o YOLO é menos propenso a predições falsas e pode localizar erros com maior eficiência.
Para isso, o YOLO utiliza uma única rede neural convolucional (CNN) para prever múltiplas caixas delimitadoras e as probabilidades associadas a essas caixas. O modelo divide a imagem em uma grade e, para cada célula da grade, prevê as caixas e suas probabilidades em apenas uma avaliação, tornando-o extremamente eficiente.
Explicando de maneira mais simplificada o funcionamento desse modelo, pode-se dizer que ele pega uma imagem e a divide em vários segmentos (ou pixels), e analisa cada um deles para buscar objetos, desenhando caixas ao redor de coisas que ele acha que são objetos. No caso do nosso projeto, ele delimita onde ele acredita que há impurezas nos canos, por se basear nos dados que foram utilizados para treiná-lo (ou ensiná-lo como identificar esses objetos). Dessa forma, cada caixa possui uma coordenada, o que indica onde está o objeto na imagem e sua largura/altura.
Após a delimitação das caixas, o modelo devolve a confiança, ou seja, qual é a probabilidade de ele estar certo quanto à detecção daquele objeto. Como mencionado anteriormente, um ponto muito positivo do YOLO é justamente essa capacidade de analisar tudo isso de uma vez só, não necessitando de processar a mesma imagem várias vezes com diferentes filtros (como é o caso, por exemplo, do Haar Cascade).
Escolha de versão
No projeto, foi decidida a utilização da versão YOLOv8, apesar de existirem atualizações mais recentes, porque a instalação é facilitada (não há a necessidade de clonar um repositório, por exemplo, como a YOLOv9), e também há mais exemplos encontrados online, facilitando o aprendizado dos desenvolvedores e implementação, já que a documentação é mais rica, o que não é o caso da versão YOLOv10, que foi lançada durante o desenvolvimento desse projeto, e ainda não tem muitos casos de uso.
Treinamento do Modelo
Dataset
Para definir o dataset, foi necessário uma série de pesquisas a fim de encontrar um que fosse o mais fiel possível e ao mesmo tempo open source para ser utilizado no projeto, uma vez que a empresa parceira não pôde disponibilizar imagens dos canos dos reboilers.
O dataset utilizado para treinar o modelo foi o Tacomare Computer Vision Project, que contém mais de 500 imagens de canos com diferentes graus de sujidade, com mais de 350 delas separadas para treino e 100 separadas para teste. Esse dataset foi escolhido por suas imagens de alta qualidade e por ser de acesso público, o que facilita a replicação dos resultados, além de facilmente aplicável para testes e utilização em razão do contexto do projeto.
Avaliação do modelo
Definição das métricas utilizadas
As métricas são indicadores que mostram como o modelo está performando, permitindo a avaliação e melhora do mesmo. As principais métricas utilizadas são a precisão, recall, mean average precision (mAP - que tem tanto o mAP50 quanto o mAP50-95) e Fitness. Agora, será apresentado o que cada uma delas representa:
-
Precisão: Apresenta a porcentagem de verdadeiros positivos (ou seja, a porcentagem predições corretas). No contexto do nosso projeto, significa em quantos canos o modelo corretamente identificou sujeiras, o que significa que ter essa métrica alta é interessante para o desempenho do projeto.
-
Recall: é uma métrica que avalia quantos objetos que deveriam ser detectados o modelo corretamente detectou. Por exemplo, se haviam 10 canos com impureza e o modelo detectou apenas 8, ele tem um recall de 80%. Isso ajuda a compreender a capacidade do modelo de encontrar a sujeira nos canos.
-
mAP50: É uma métrica que utiliza de um threshold de 50%, que nada mais é que um valor que determina a precisão que uma detecção precisa performar para ser considerada correta. Por exemplo, com um threshold de 50% significa que, para uma detecção ser considerada correta, a sobreposição entre a caixa predita pelo modelo e a caixa real do objeto deve ser de pelo menos 50%. É uma métrica mais simples para avaliar o desempenho do modelo.
-
mAP50-95: Possui a mesma lógica do anterior, mas possui um threshold variável entre 50% a 95%, com intervalos de 5%, dando uma visão mais completa do modelo, pois avalia quão bem ele se sai em diferentes níveis de sobreposição, sendo um pouco mais rigoroso que o mAP50.
Resultados
Para uma visualização mais clara dos resultados obtidos com o treinamento do modelo, é possível observar no gráfico abaixo o desempenho dele nas métricas precisão, recall e mAP50-95 durante cada uma das 200 épocas de treinamento, que indicam o número de vezes que o modelo passou por todo o dataset de treinamento.
Níveis de Precisão, Recall e mAP50-95 em 200 épocas
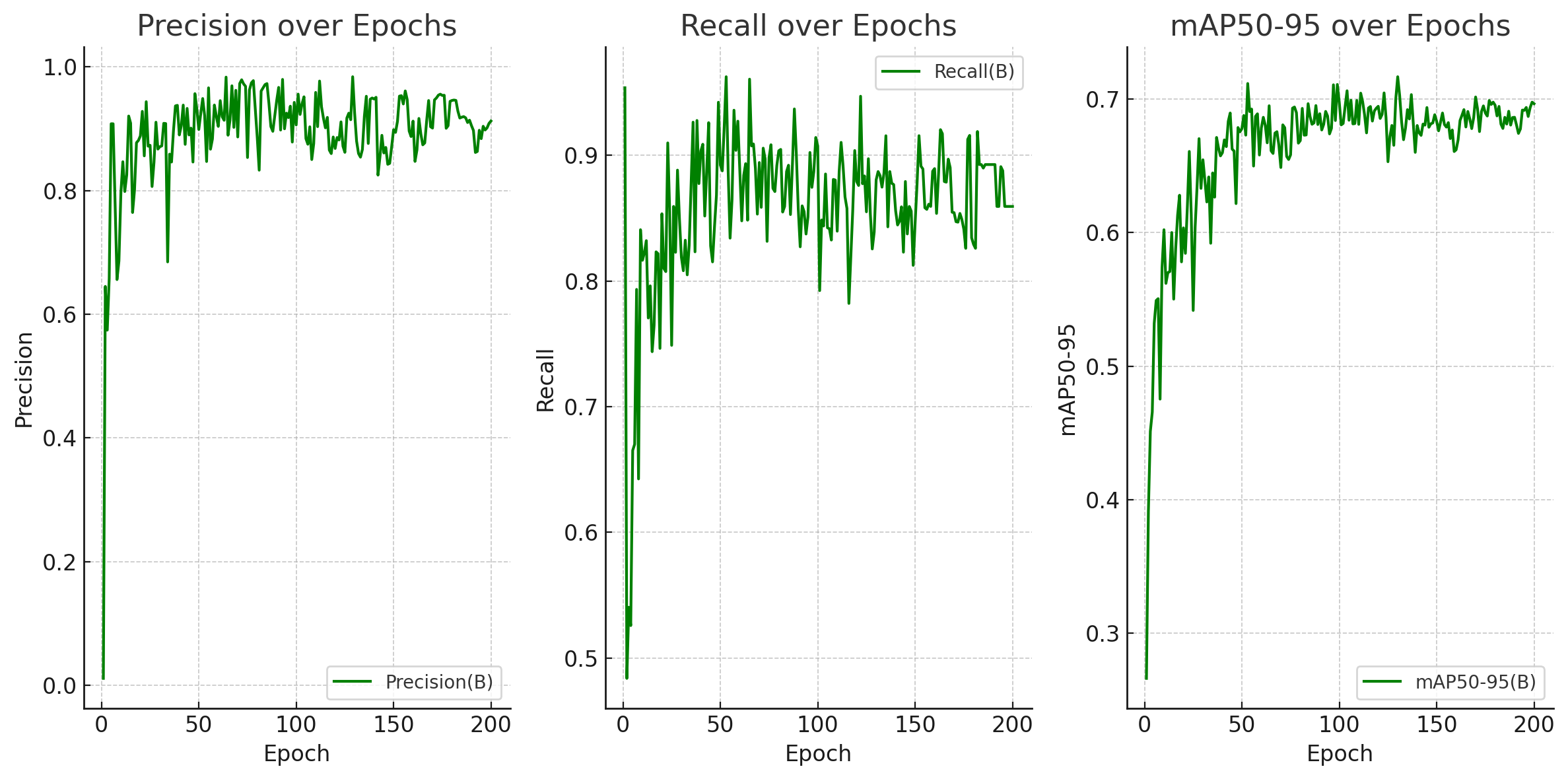
Fonte: Elaborado pela equipe Rebólins
Como é possível observar nos gráficos acima, o modelo alcançou uma precisão estável entre 80% e 90% em todas as métricas testadas, indicando uma alta capacidade de detecção de sujeira nos canos de reboilers. Além disso, o modelo apresentou um alto recall, demonstrando ser capaz de detectar a maioria dos objetos presentes nas imagens.
Bibliografia
[1] ALVES, Gabriel. Detecção de Objetos com YOLO – Uma abordagem moderna. Disponível em: https://iaexpert.academy/2020/10/13/deteccao-de-objetos-com-yolo-uma-abordagem-moderna/?doing_wp_cron=1717618413.5629088878631591796875. Acesso em: 06 de junho de 2024.
[2] REDMON, Joseph; DIVVALA, Santosh; GIRSHICK, Ross; FARHADI, Ali. You Only Look Once: Unified, Real-Time Object Detection. Disponível em: https://arxiv.org/abs/1506.02640. Acesso em: 06 de junho de 2024.