Modelo: Segment Anything
Este modelo desenvolvido pela SOD utiliza o modelo Segment Anything, da Meta AI, como um dos modelos de teste para realizarmos a detecção ou a segmentação das fissuras, de maneira a identificar nas imagens enviadas se haviam fissuras ou rachaduras presentes nas imagens. O modelo não apresentou resultados satisfatórios considerando seu objetivo de implementação.
Segment Anything
Antes de abordarmos o processo de treinamento do modelo, é importante compreendermos como o Segment Anything Model (SAM) funciona em sua pŕatica. Trata-se de um modelo de segmentação com capacidade de operar tanto de forma interativa quanto automática, com base na simples formulação de prompts apropriados. Sua arquitetura foi projetada para aceitar diferentes formas de entrada – como cliques, caixas delimitadoras e, em versões estendidas, até mesmo instruções textuais – permitindo que o mesmo modelo seja utilizado de maneira altamente flexível em uma ampla variedade de aplicações.
Essa versatilidade é sustentada por um treinamento de larga escala: o SAM foi treinado sobre um dos maiores conjuntos de dados de segmentação já construídos, composto por mais de 1 bilhão de máscaras. Isso conferiu ao modelo uma capacidade de generalização notável, permitindo que ele seja utilizado em contextos fora da sua distribuição de treinamento original, segmentando com precisão objetos e padrões visuais não observados previamente.
Como o SAM foi utilizado?
Como dito no tópico anterior, o modelo tem potencial de atuação fora da sua distribuição de treinamento original, mas para adaptar o modelo ao nosso domínio a fim de obtermos resultados mais precisos, utilizamos duas ferramentas:
- Nosso dataset ja separado, com imagens e labels, com o roboflow
- A técnica de prompting do SAM, usando caixas ou pontos para guiar a segmentação (similar ao método usado nos tutoriais de fine‑tuning da Encord e outros)
Embora essa abordagem seja popular — e recomendada por diversos guias — para adaptar o SAM a domínios específicos, os resultados nem sempre são eficazes sem volume suficiente de dados e prompts apropriados. Com isso, não alcançamos a confiabilidade que gostariamos nos resultados, uma vez que ele gerou máscaras erradas ou imprecisas em muitos dos casos.
Com o modelo de predição definido, definimos também os filtros de pré-processamento, escolhidos anteriormente pelo grupo, para auxiliar no aumento da acurácia e precisão na identificação das fissuras quando enviadas ao modelo junto com o prompt, mas novamente o resultado não foi satisfatório, como mostram as imagens a seguir:
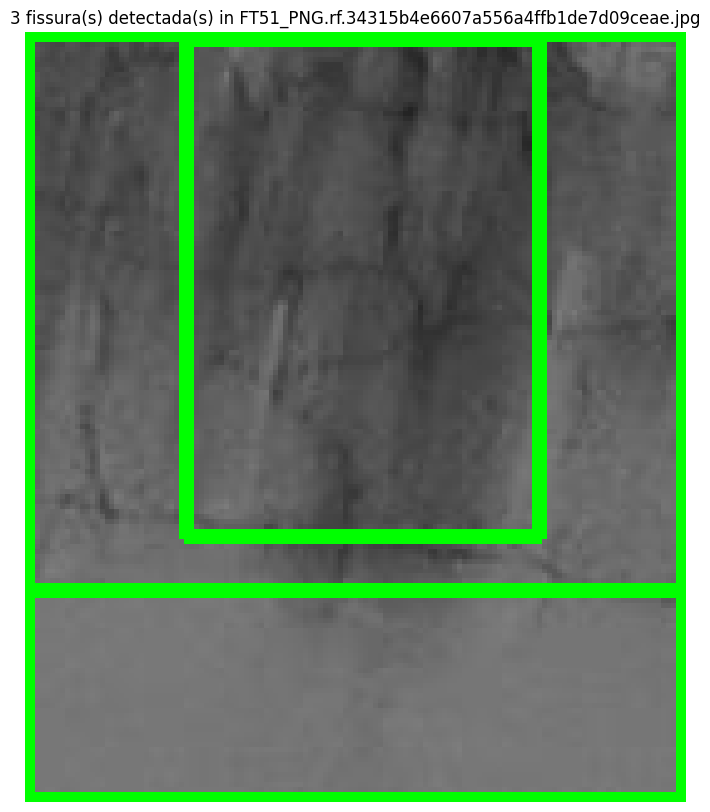

É importante ressaltar que nas imagens em que o modelo destacava mais de uma fissura identificada, o "score" (ou confiabilidade) para aquelas fissuras ia aumentando conforme o campo de cada fissura diminuia, ou seja, as menores caixas de fissuras identificadas nas imagens eram as que geravam um score mais alto dentro do que o modelo seguia com base no treinamento dele. Embora esse "score" tenha sido alto em alguns dos casos, o modelo falha uma vez que não identifica corretamente todas as fissuras presentes nas imagens de maneira mais individual e apresenta segmentações muito generalizadas (como quando ele identifica a imagem inteira como uma fissura). Nosso diagnóstico é que, mesmo usando os tutoriais, as segmentações resultantes não atingem o nível de qualidade desejado para implementação oficial do modelo.
Limitações encontradas e possíveis causas para o resultado
Analisando não só os resultados mas também o processo de treinamento do modelo, podemos identificar possíveis causas para um resultado não satisfatório:
-
Domínio fora da distribuição e precisão nos prompts: embora seja um modelo pré-treinado, o SAM tende a falhar em dados muito específicos ou imagens com padrões fora do conjunto de origem, dependendo altamente de prompts precisos (pontos) para gerar resultados mais confiáveis.
-
Quantidade limitada de dados para o treinamento do modelo: o dataset enviado para o modelo pode nao ter sido suficiente para criação de mascaras mais específicas com o mask decoder.
Considerando esses pontos, percebemos que, provavelmente, ganhos significativos com o SAM só aparecem com uma combinação de domínios específicos, prompts bem estruturados e um volume suficiente de dados anotados, o que requer um esforço elevado considerando custos computacionais.
Conclusão
O Segment Anything Model (SAM) é um modelo muito inovador e promissor, mas muito exigente em termos de domínio, qualidade de prompt e quantidade de dados. Com isso, seu uso em nosso domínio mostrou-se pouco eficaz sem ajustes maiores considerando custos e tempo de desenvolvimento disponível. Por isso, seguimos com uma solução mais aderente às nossas necessidades atuais, que é um outro modelo treinado, avaliado como mais adequado até o momento para as próximas etapas do projeto.